
9. 交互二开使用指南
9. 交互二开使用指南
交互相关的端侧二次开发提供两类开发模式:
- 智元交互简单拓展
- 智元交互能力保留,由智元提供 tts 和动作表情等基本接口,可以通过这些接口操作机器人进行基本展厅导览、讲解等流程,同时机器人可正常走智元语音交互方案。
- 二次开发完全接管
- 关闭智元交互能力,由智元提供包含本体降噪后的机器人麦克风输入,开放扬声器使用权限及人脸识别结果,完全由二次开发程序接管语音交互相关内容。
以下为二者详细对比表格
| 模式 | 智元交互能力是否保留 | 智元侧提供接口 | 联网需求 | 适用场景 | 开发难度及工作量 |
|---|---|---|---|---|---|
| 智元交互简单拓展 | 是 | tts、动作、表情、人脸识别接口 | 智元交互方案以及 tts 接口都需要联网 | 开发简单展厅导览演示 demo,固定流程编排 | 较为简单,工作量取决于流程复杂程度,一般较小 |
| 二次开发完全接管 | 否 | 降噪音频、扬声器、人脸识别接口 | 机器人初始化时需要联网,后续使用无需联网 | 自行开发完整交互方案 | 难度较大,需要有完整的相关研发团队,工作量较大 |
9.1 智元交互简单拓展
在此类开发模式下,可以调用的接口如下:
| 接口名/订阅主题 | 接口描述 | 请求消息类型 | 答复消息类型 | 备注 | 通信后端 |
|---|---|---|---|---|---|
TTSService.PlayTTS | 文本转语音播放 | PlayTTSRequest | PlayTTSResponse | 支持优先级控制和打断策略 | http |
TTSService.PlayMediaFile | 播放本地音频文件 | PlayMediaFileRequest | PlayTTSResponse | 支持 PCM/WAV 格式文件播放 | http |
TTSService.GetAudioStatus | 查询 TTS/音频文件状态 | GetTTSStatusRequest | GetTTSStatusResponse | 获取当前播报状态和队列信息 | http |
/interaction/tts_status | 查询 TTS/音频文件状态 | TTSStatus | - | 获取当前播报状态和队列信息 | ros2 |
TTSService.StopTTSTraceId | 停止指定 id 的 TTS/音频文件播报 | StopTTSTraceIdRequest | CommonResponse | 仅终止指定 trace_id 的播报任务 | http |
TTSService.StopTTS | 停止所有 TTS/音频文件播报 | CommonRequest | CommonResponse | 终止当前播报和所有队列中的任务 | http |
HalAudioService.GetAudioVolume | 音量获取 | CommonRequest | VolumeResponse | 获取当前音量大小 | http |
HalAudioService.SetAudioVolume | 音量设置 | VolumeRequest | AudioCommonResponse | 调节当前音量大小 | http |
MotionCommandService.SendMotionCommand | 播放指定动作文件 | MotionCommandRequest | CommonResponse | 仅可在 JOINT_SERVO 后缀的运控 Action 下调用 | http |
MotionCommandService.GetMotionStatus | 查询动作播放状态 | CommonRequest | MotionCommandResponse | 获取当前动作播放状态 | http |
ResourceService.GetMotion | 获取动作列表 | GetMotionReq | GetMotionResp | 路径可在 x86 上找到对应文件 | http |
RcMotionPlayerService.PlayerMotion | 播放指定 id 的动作 | RcPlayerMotionRequest | CommonResponse | 仅可在 JOINT_SERVO 后缀的运控 Action 下调用 | http |
ResourceService.GetEmoticon | 获取表情列表 | GetEmoticonReq | GetEmoticonResp | 路径可在 x86 上找到对应文件 | http |
RcEmoticonPlayerService.PlayerEmoticon | 播放指定 id 的表情 | RcPlayerEmoticonRequest | RcPlayerEmoticonResponse | 仅播放指定 motion_id 的表情 | http |
/agent/vision/face_id | 人脸识别结果 | FaceIdResult | - | 需要source环境后使用 | ros2 |
交互相关接口的详细信息可参考 动作播放部分、表情播放部分、 TTS/音频播放部分和麦克风管理部分 接口文档进行调用。交互相关接口的示例文件在 AimDK 包中 examples/rc, examples/motion_player, examples/agent 和 examples/hal_audio 目录下均有提供,可参考。
9.2 二次开发完全接管
智元交互链路涉及到的模块一共有两个,分别为 agent 和 hal_audio,可以简单理解为 agent 模块管理麦克风部分,hal_audio 模块管理扬声器部分。agent 模块采集音频并进行语音识别,然后与云端模型交互,得到结果后发送给 hal_audio 模块,hal_audio 模块再根据结果进行相应的语音播放、动作、表情等操作。
9.2.1 退出智元交互链路
在此模式下,需要让智元的交互程序退出交互链路,仅输出包含本体降噪后的麦克风音频、人脸识别结果并让出扬声器的控制权,需要进行的操作有两个:
- 调整 agent 模块为 only_voice / voice_face 模式,可以使用麦克风管理部分
SetAgentPropertiesRequest接口。
- only_voice:仅输出降噪麦克音频 /agent/process_audio_output,后续链路全部断开
- voice_face:输出降噪麦克音频 /agent/process_audio_output 和人脸识别结果 /agent/vision/face_id,后续链路全部断开
例如调整为 only_voice 模式所需调用的 rpc 如下:bashcurl -i \ -H 'content-type:application/json' \ -X POST 'http://192.168.100.110:59301/rpc/aimdk.protocol.AgentControlService/SetAgentPropertiesRequest' \ -d '{ "contents": { "properties": { "2": "only_voice" } } }'
调用后需要重启机器人才能生效,可以待第二步的修改完成后再一块重启即可。重启后可以通过使用麦克风管理部分GetAgentPropertiesRequest接口查询当前交互运行模式,判断模式是否修改成功。 (如需恢复,则将SetAgentPropertiesRequest接口中的 "only_voice / voice_face" 改为 "normal" 即可)
- 修改配置默认不启动 hal_audio 模块(修改一次即可,后续无需重复修改)
首先备份 ORIN 上的 /agibot/software/v0/entry/bin/cfg/run_agibot.yaml 文件bashcp /agibot/software/v0/entry/bin/cfg/run_agibot.yaml /agibot/software/v0/entry/bin/cfg/run_agibot.yaml.backup
然后在 run_agibot.yaml 文件中删除 default_apps 中的 hal_audio 模块,其他部分不要修改。改完成后重启机器人。(如需恢复,则将以上文件还原并重启机器人即可)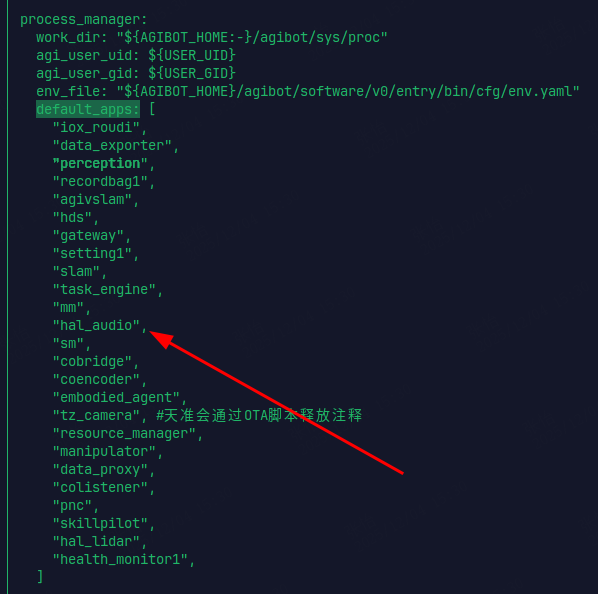
以上操作完成后智元交互已退出交互链路。
9.2.2 麦克风音频获取
注意:要获取以下音频需要机器人开机时至少联网 2 分钟以上完成音频相关鉴权操作,否则将无原始音频输出,如需离线使用,请首先保证该接口有音频输出后再断网
退出交互链路后,可通过降噪麦克音频 Topic 接口 /agent/process_audio_output 获得本体降噪后的麦克风音频信息。获取本体降噪后的麦克风音频示例程序如下:
#!/usr/bin/env python3
import rclpy
from rclpy.node import Node
from rclpy.qos import QoSHistoryPolicy, QoSProfile, QoSReliabilityPolicy
from ros2_plugin_proto.msg import RosMsgWrapper
from aimdk.protocol_pb2 import ProcessedAudioOutput, AudioVADState
import datetime
import os
class AudioSubscriber(Node):
def __init__(self):
super().__init__("audio_subscriber")
# 音频缓冲区,按 stream_id 分别存储
self.audio_buffers = {} # {stream_id: bytearray()}
self.recording_state = {} # {stream_id: bool} 记录是否正在录音
# 创建音频文件存储目录
self.audio_output_dir = "audio_recordings"
os.makedirs(self.audio_output_dir, exist_ok=True)
qos_profile = QoSProfile(
history=QoSHistoryPolicy.KEEP_LAST,
depth=10,
reliability=QoSReliabilityPolicy.BEST_EFFORT,
)
self.subscription = self.create_subscription(
RosMsgWrapper,
"/agent/process_audio_output/pb_3Aaimdk_2Eprotocol_2EProcessedAudioOutput",
self.audio_callback,
qos_profile,
)
self.get_logger().info("开始订阅降噪音频数据。..")
def audio_callback(self, msg):
try:
# 检查序列化类型是否为 pb
if msg.serialization_type != "pb":
self.get_logger().warn(f"不支持的序列化类型:{msg.serialization_type}")
return
# 将 data 字段从 list[bytes] 转换为 bytes
audio_data_bytes = b"".join(msg.data)
# 使用生成的 protobuf 类解析消息
processed_audio = ProcessedAudioOutput()
processed_audio.ParseFromString(audio_data_bytes)
self.get_logger().info(
f"收到音频数据:stream_id={processed_audio.stream_id}, "
f"vad_state={processed_audio.vad_state}, "
f"audio_size={len(processed_audio.audio_data)} bytes"
)
# 根据 VAD 状态处理音频
self.handle_vad_state(processed_audio)
except Exception as e:
self.get_logger().error(f"处理音频消息时出错:{e}")
def handle_vad_state(self, processed_audio):
"""处理不同的 VAD 状态"""
vad_state = processed_audio.vad_state
stream_id = processed_audio.stream_id
audio_data = processed_audio.audio_data
# 初始化该 stream_id 的缓冲区(如果不存在)
if stream_id not in self.audio_buffers:
self.audio_buffers[stream_id] = bytearray()
self.recording_state[stream_id] = False
# VAD 状态名称映射
vad_state_names = {
AudioVADState.AUDIO_VAD_STATE_NONE: "无语音",
AudioVADState.AUDIO_VAD_STATE_BEGIN: "语音开始",
AudioVADState.AUDIO_VAD_STATE_PROCESSING: "语音处理中",
AudioVADState.AUDIO_VAD_STATE_END: "语音结束",
}
stream_names = {1: "内置麦克风", 2: "外置麦克风"}
self.get_logger().info(
f"[{stream_names.get(stream_id, f'未知流{stream_id}')}] "
f"VAD 状态:{vad_state_names.get(vad_state, f'未知状态{vad_state}')} "
f"音频数据:{len(audio_data)} bytes"
)
# 根据 VAD 状态处理音频数据
if vad_state == AudioVADState.AUDIO_VAD_STATE_BEGIN:
self.get_logger().info("🎤 检测到语音开始")
# 开始新的录音,清空缓冲区
self.audio_buffers[stream_id].clear()
self.recording_state[stream_id] = True
# 添加当前音频数据
if len(audio_data) > 0:
self.audio_buffers[stream_id].extend(audio_data)
elif vad_state == AudioVADState.AUDIO_VAD_STATE_PROCESSING:
self.get_logger().info("🔄 语音处理中。..")
# 如果正在录音,继续添加音频数据到缓冲区
if self.recording_state[stream_id] and len(audio_data) > 0:
self.audio_buffers[stream_id].extend(audio_data)
elif vad_state == AudioVADState.AUDIO_VAD_STATE_END:
self.get_logger().info("✅ 语音结束")
# 添加最后的音频数据
if self.recording_state[stream_id] and len(audio_data) > 0:
self.audio_buffers[stream_id].extend(audio_data)
# 保存完整的音频段
if (
self.recording_state[stream_id]
and len(self.audio_buffers[stream_id]) > 0
):
self.save_audio_segment(bytes(self.audio_buffers[stream_id]), stream_id)
# 结束录音
self.recording_state[stream_id] = False
elif vad_state == AudioVADState.AUDIO_VAD_STATE_NONE:
# 无语音状态,不进行录音
if self.recording_state[stream_id]:
self.get_logger().info("⏹️ 录音状态重置")
self.recording_state[stream_id] = False
# 输出当前缓冲区状态
if stream_id in self.audio_buffers:
buffer_size = len(self.audio_buffers[stream_id])
recording = self.recording_state[stream_id]
self.get_logger().debug(
f"[Stream {stream_id}] 缓冲区大小:{buffer_size} bytes, 录音状态:{recording}"
)
def save_audio_segment(self, audio_data, stream_id):
"""保存音频段 16kHz, 16 位,单声道 PCM"""
if len(audio_data) > 0:
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S_%f")
# 按 stream_id 创建子目录
stream_dir = os.path.join(self.audio_output_dir, f"stream_{stream_id}")
os.makedirs(stream_dir, exist_ok=True)
# 生成文件名
stream_names = {1: "internal_mic", 2: "external_mic"}
stream_name = stream_names.get(stream_id, f"stream_{stream_id}")
filename = f"{stream_name}_{timestamp}.pcm"
filepath = os.path.join(stream_dir, filename)
try:
with open(filepath, "wb") as f:
f.write(audio_data)
self.get_logger().info(
f"音频段已保存:{filepath} (大小:{len(audio_data)} bytes)"
)
# 记录音频文件的时长(假设 16kHz, 16 位,单声道)
sample_rate = 16000
bits_per_sample = 16
channels = 1
bytes_per_sample = bits_per_sample // 8
total_samples = len(audio_data) // (bytes_per_sample * channels)
duration_seconds = total_samples / sample_rate
self.get_logger().info(
f"音频时长:{duration_seconds:.2f} 秒 ({total_samples} 样本)"
)
except Exception as e:
self.get_logger().error(f"保存音频文件失败:{e}")
def get_buffer_info(self):
"""获取所有缓冲区的信息(用于调试)"""
info = {}
for stream_id in self.audio_buffers:
info[stream_id] = {
"buffer_size": len(self.audio_buffers[stream_id]),
"recording": self.recording_state[stream_id],
}
return info
def main(args=None):
rclpy.init(args=args)
audio_subscriber = AudioSubscriber()
try:
audio_subscriber.get_logger().info("正在监听降噪音频数据,按 Ctrl+C 退出。..")
rclpy.spin(audio_subscriber)
except KeyboardInterrupt:
audio_subscriber.get_logger().info("收到退出信号,正在关闭。..")
finally:
audio_subscriber.destroy_node()
rclpy.shutdown()
if __name__ == "__main__":
main()
以上程序依赖 python 协议包 a2_aimdk 和 ros2 协议包 ros2_plugin_proto,相应的包已经放置在 AimDK 开发包的 prebuilt 目录下,python 包使用 pip install prebuilt/a2_aimdk-1.0.0-py3-none-any.whl 安装,ros2 包需要 source prebuilt/ros2_plugin_proto_aarch64/share/ros2_plugin_proto/local_setup.bash后使用。
请注意,以上程序会接收 ros2 消息,需要设置如下环境变量:
source /opt/ros/humble/setup.bash
export ROS_DOMAIN_ID=232
export ROS_LOCALHOST_ONLY=0
export FASTRTPS_DEFAULT_PROFILES_FILE=/agibot/software/v0/entry/bin/cfg/ros_dds_configuration.xml
其中音频数据为 16kHz 采样率,16 位单声道 PCM 数据(小端序),输出的音频为纯净人声,已经过降噪处理,回声消除等,可以直接用于 ASR 识别。
ProcessedAudioOutput消息包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| header | Header | 通用消息头,包含时间戳和消息 ID |
| stream_id | uint32 | 音频流 ID(1:内置麦克风,2:外置麦克风) |
| vad_state | AudioVADState | 语音活动检测状态 |
| audio_data | bytes | 降噪处理后的 PCM 音频数据 |
AudioVADState 枚举定义:
| 枚举值 | 数值 | 说明 |
|---|---|---|
| AUDIO_VAD_STATE_NONE | 0 | 无语音 |
| AUDIO_VAD_STATE_BEGIN | 1 | 语音开始 |
| AUDIO_VAD_STATE_PROCESSING | 2 | 语音处理中 |
| AUDIO_VAD_STATE_END | 3 | 语音结束 |
注意:当前版本外置麦克风的接口输出 vad_state 存在问题,预期一条语音输入的状态为 122222222223,实际输出的状态为 0111111111112,此问题仅在外置麦场景下出现(内置麦正常),并计划在后续版本修复。当前版本建议手动对状态执行 +1 补偿。
9.2.3 扬声器音频播放
注意:机器人扬声器音量设置不得超过 70%,音量超出此范围扬声器经功放放大后会超额定工作,造成扬声器损坏
可使用下面的设备进行播放,程序调用请自行实现,音频声道、逻辑设备等配置可查看 ORIN 上 /etc/asound.conf 文件。
aplay -D multiplay_def -c 1 -r 24000 -f S16_LE /agibot/data/var/interaction/audio/wake.pcm
音量调节指令如下:
- P1 机器
- 设置播放音量
amixer cset name='x Headphone Volume' 15(0~31)
- 获取播放音量
amixer cget name='x Headphone Volume'
- 设置静音
amixer sset 'x Headphone Left' off
amixer sset 'x Headphone Right' off
- 解除静音
amixer sset 'x Headphone Left' on
amixer sset 'x Headphone Right' on
- T3 机器
- 设置播放音量
amixer -c DefPDevice sset Speaker 80%(0~100%)
- 获取播放音量
amixer -c DefPDevice sget Speaker
- 设置静音
amixer -c DefPDevice set Speaker off
- 解除静音
amixer -c DefPDevice set Speaker on
9.2.4 人脸识别
注意:若在获取人脸识别结果前,执行了“7.4.4 摄像头设备释放”中针对交互相机的释放操作,相机数据流将中断,导致人脸识别无法获取图像数据,从而影响功能正常使用。
若 agent 设置为 voice_face 模式,除输出降噪麦克音频 Topic 接口外,同时返回人脸识别结果 Topic 接口 /agent/vision/face_id,only_voice 模式下无此消息
获取人脸识别结果示例程序如下:
#!/usr/bin/env python3
import rclpy
from rclpy.node import Node
from rclpy.qos import QoSHistoryPolicy, QoSProfile, QoSReliabilityPolicy
from ros2_plugin_proto.msg import RosMsgWrapper
from aimdk.protocol_pb2 import FaceIdResult
class FaceIdSubscriber(Node):
def __init__(self):
super().__init__("face_id_subscriber")
qos_profile = QoSProfile(
history=QoSHistoryPolicy.KEEP_LAST,
depth=10,
reliability=QoSReliabilityPolicy.BEST_EFFORT,
)
self.subscription = self.create_subscription(
RosMsgWrapper,
"/agent/vision/face_id/pb_3Aaimdk_2Eprotocol_2EFaceIdResult",
self.face_id_callback,
qos_profile,
)
self.get_logger().info("已开始订阅 FaceID 数据...")
def face_id_callback(self, msg):
try:
if msg.serialization_type != "pb":
self.get_logger().warn(
f"收到不支持的序列化类型: {msg.serialization_type}"
)
return
# 拼接 bytes
raw_bytes = b"".join(msg.data)
# 解析 protobuf
face_id_result = FaceIdResult()
face_id_result.ParseFromString(raw_bytes)
# 日志输出
import json
from google.protobuf.json_format import MessageToDict
self.get_logger().info(
f"FaceID 结果: {json.dumps(MessageToDict(face_id_result, preserving_proto_field_name=True), ensure_ascii=False, indent=2)}")
except Exception as e:
self.get_logger().error(f"解析 FaceID 数据时出现错误: {e}")
def main(args=None):
rclpy.init(args=args)
node = FaceIdSubscriber()
try:
node.get_logger().info("正在监听 FaceID 数据,按 Ctrl+C 退出...")
rclpy.spin(node)
except KeyboardInterrupt:
node.get_logger().info("退出中...")
finally:
node.destroy_node()
rclpy.shutdown()
if __name__ == "__main__":
main()
以上程序依赖 python 协议包 a2_aimdk 和 ros2 协议包 ros2_plugin_proto,相应的包已经放置在 AimDK 开发包的 prebuilt 目录下,python 包使用 pip install prebuilt/a2_aimdk-2.0.1-py3-none-any.whl 安装,ros2 包需要 source prebuilt/ros2_plugin_proto_aarch64/share/ros2_plugin_proto/local_setup.bash后使用。
请注意,以上程序会接收 ros2 消息,需要设置如下环境变量:
source /opt/ros/humble/setup.bash
export ROS_DOMAIN_ID=232
export ROS_LOCALHOST_ONLY=0
export FASTRTPS_DEFAULT_PROFILES_FILE=/agibot/software/v0/entry/bin/cfg/ros_dds_configuration.xml
同时提供了本地人脸注册接口,该接口非常规 HTTP JSON RPC 或 ROS2 Topic,而是单独提供了一个调用脚本 examples/agent/run_face_id_register.sh,其内容如下:
#!/bin/bash
# 1. 要注册的 images 目录(sh脚本同级)
RUN_SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
IMAGES_DIR="${RUN_SCRIPT_DIR}/images"
# 2. Faceid base目录
FACEID_SCRIPT_DIR="/agibot/software/v0/scripts/agent/face_id/"
FACEID_LIB_DIR="/agibot/software/v0/bin"
FACEID_OFFLINE_FEAT="/agibot/data/param/interaction/face_id/offline_face_features"
# 3. 可执行文件与配置文件的相对路径
EXEC="${FACEID_SCRIPT_DIR}/face_id_register"
CONF="${FACEID_SCRIPT_DIR}/face_id_config.json"
chmod +x "$EXEC"
export LD_LIBRARY_PATH="${FACEID_LIB_DIR}":$LD_LIBRARY_PATH
# 4. 调用
rm -rf "$FACEID_OFFLINE_FEAT"/*
"$EXEC" "$CONF" "$IMAGES_DIR"
将需要注册的人脸数据放置到脚本同目录下的 images 目录中,在 ORIN 上执行该脚本即可完成注册,注册完成后 ID 与图片对应关系以及是否成功注册的结果都存储在同目录下的 Result.txt 文件中,示例如下(其中模糊和人脸过小也注册成功了,但是实际使用中仍推荐使用 满足.png 中展示的清晰正面人脸图像,以免对识别率等造成不良影响):
GID17648293009168001 满足.png OK 注册成功
GID17648293018063607 侧脸.png FAIL 人脸质量不满足要求
GID17648293020281011 过暗.png FAIL 人脸质量不满足要求
GID17648293021878934 模糊.png OK 注册成功
GID17648293024764703 过曝.png FAIL 人脸质量不满足要求
GID17648293026684491 无人脸.png FAIL 未检测到人脸
GID17648293028768487 非人脸.png FAIL 未检测到人脸
GID17648293030305970 人脸过小.png OK 注册成功
人脸注册识别逻辑规则说明:
- images 目录中存放 jpg、png、jpeg类型的人脸图片,图片只存在一个正面清晰的人脸,运行脚本即可注册。注册后需要重启 agent,在 ORIN 上运行
aima em stop-app agent && aima em start-app agent即可,也可直接重启机器人。 - 本地注册的人脸特征会存放在 ORIN 上 /agibot/data/param/interaction/face_id/offline_face_features 目录下。
- 注册的用户 ID 的构建规则是:“GID” + 时间戳 + 随机4位数;发布时会将当前机器的 SN (/agibot/data/info/sn)替换 “GID” 作为新的 UID 发布
- 另外灵心平台一样可以上传人脸,我们称之为云端人脸数据库,云端人脸数据库可配置打招呼等等信息,相应内容下发后会下发后存储在 ORIN 上 /agibot/data/param/interaction/face_id/user_info.json 文件中。
- 上述脚本每次注册会将原有的本地数据库清空,请每次都完整将所有人脸数据都重新注册,即维护一个 images 文件夹,其中包含所有需要识别的人脸图像,有任何增删改需重新运行注册脚本。
- 匹配规则永远是优先匹配云端数据库然后再匹配本地数据库,找到第一个匹配成功的人脸后不会继续匹配剩余人脸。
9.2.5 唤醒结果上报
若 agent 设置为 only_voice 模式,唤醒结果上报 Topic 接口为 /agent/wakeup/pb_3Aaimdk_2Eprotocol_2EWakeUpResult
获取唤醒结果上报示例程序如下:
#!/usr/bin/env python3
import rclpy
from rclpy.node import Node
from rclpy.qos import (
QoSDurabilityPolicy,
QoSHistoryPolicy,
QoSProfile,
QoSReliabilityPolicy,
)
from ros2_plugin_proto.msg import RosMsgWrapper
from aimdk.protocol_pb2 import WakeUpResult
TOPIC = "/agent/wakeup/pb_3Aaimdk_2Eprotocol_2EWakeUpResult"
class WakeUpSubscriber(Node):
def __init__(self):
super().__init__("wakeup_result_subscriber")
qos_profile = QoSProfile(
history=QoSHistoryPolicy.KEEP_LAST,
depth=10,
reliability=QoSReliabilityPolicy.RELIABLE,
durability=QoSDurabilityPolicy.VOLATILE,
)
self.subscription = self.create_subscription(
RosMsgWrapper,
TOPIC,
self.wakeup_callback,
qos_profile,
)
self.get_logger().info(f"已开始订阅 WakeUpResult: {TOPIC}")
def wakeup_callback(self, msg):
try:
if msg.serialization_type != "pb":
self.get_logger().warn(
f"收到不支持的序列化类型: {msg.serialization_type}"
)
return
# 拼接 bytes
raw_bytes = b"".join(msg.data)
# 解析 protobuf
wakeup_result = WakeUpResult()
wakeup_result.ParseFromString(raw_bytes)
# 日志输出
import json
from google.protobuf.json_format import MessageToDict
self.get_logger().info(
f"WakeUpResult: {json.dumps(MessageToDict(wakeup_result, preserving_proto_field_name=True), ensure_ascii=False, indent=2)}"
)
except Exception as e:
self.get_logger().error(f"解析 WakeUpResult 数据时出现错误: {e}")
def main(args=None):
rclpy.init(args=args)
node = WakeUpSubscriber()
try:
node.get_logger().info("正在监听 WakeUpResult,按 Ctrl+C 退出...")
rclpy.spin(node)
except KeyboardInterrupt:
node.get_logger().info("退出中...")
finally:
node.destroy_node()
rclpy.shutdown()
if __name__ == "__main__":
main()
以上程序依赖 python 协议包 a2_aimdk 和 ros2 协议包 ros2_plugin_proto,相应的包已经放置在 AimDK 开发包的 prebuilt 目录下,python 包使用 pip install prebuilt/a2_aimdk-2.0.1-py3-none-any.whl 安装,ros2 包需要 source prebuilt/ros2_plugin_proto_aarch64/share/ros2_plugin_proto/local_setup.bash后使用。
请注意,以上程序会接收 ros2 消息,需要设置如下环境变量:
source /opt/ros/humble/setup.bash
export ROS_DOMAIN_ID=232
export ROS_LOCALHOST_ONLY=0
export FASTRTPS_DEFAULT_PROFILES_FILE=/agibot/software/v0/entry/bin/cfg/ros_dds_configuration.xml