交互二次开发指南
交互二次开发指南
Section titled “交互二次开发指南”本文档详细交互相关二次开发的推荐流程以及相关接口使用方法。
交互二开分类
Section titled “交互二开分类”交互相关的端侧二次开发提供两类开发模式
- 智元交互简单拓展
- 智元交互能力保留,由智元提供 tts 和动作表情等基本接口,可以通过这些接口操作机器人进行基本展厅导览、讲解等流程,同时机器人可正常走智元语音交互方案。
- 二次开发完全接管
- 关闭智元交互能力,由智元提供包含本体降噪后的机器人麦克风输入,开放扬声器使用权限,完全由二次开发程序接管语音交互相关内容。
以下为二者详细对比表格
| 模式 | 智元交互能力是否保留 | 智元侧提供接口 | 联网需求 | 适用场景 | 开发难度及工作量 |
|---|---|---|---|---|---|
| 智元交互简单拓展 | 是 | tts、动作、表情接口 | 智元交互方案以及 tts 接口都需要联网 | 开发简单展厅导览演示 demo,固定流程编排 | 较为简单,工作量取决于流程复杂程度,一般较小 |
| 二次开发完全接管 | 否 | 降噪音频接口,扬声器系统接口 | 机器人初始化时需要联网,后续使用无需联网 | 自行开发完整交互方案 | 难度较大,需要有完整的相关研发团队,工作量较大 |
智元交互简单拓展
Section titled “智元交互简单拓展”TTS 接口调用示例
Section titled “TTS 接口调用示例”curl -i \ -H 'content-type:application/json' \ -X POST 'http://192.168.100.110:59201/rpc/aimdk.protocol.TTSService/PlayTTS' \ -d '{"text":"测试文本","priority_level":"INTERACTION_L6","domain":"example", "trace_id":"hafhjkqwjwefk", "is_interrupted":true}'其中各个字段含义如下:
| 字段名 | 类型 | 必要性 | 说明 |
|---|---|---|---|
| header | RequestHeader | 必要 | 通用请求头(含 ID、时间戳) |
| text | string | 必要 | 待合成文本内容 |
| priority_level | PriorityLevel | 必要 | 优先级 |
| domain | string | 必要 | 调用方标识 |
| trace_id | string | 必要 | 如果需要获取播报状态,则需要传入该字段,并将其值作为查询播报状态的参数 |
| is_interrupted | bool | 必要 | 是否打断同等优先级播报,请默认传 true,有队列播报的需求可以使用 false |
相应优先级定义如下(常规语音交互推荐使用 INTERACTION_L6):
| 枚举值 | 数值 | 说明 |
|---|---|---|
| BACKGROUND_L1 | 1 | 后台服务层(最低) |
| SERVICE_L2 | 2 | 主动服务层 |
| MISSION_L4 | 4 | 任务执行层 |
| INTERACTION_L6 | 6 | 交互响应层(默认) |
| WARNING_L8 | 8 | 危险预警层 |
| SAFETY_L10 | 10 | 生命安全层(最高) |
音频文件播放接口调用示例
Section titled “音频文件播放接口调用示例”curl -i \ -H 'content-type:application/json' \ -X POST 'http://192.168.100.110:59201/rpc/aimdk.protocol.TTSService/PlayMediaFile' \ -d '{"file_name": "custom/wake.pcm","priority_level":"INTERACTION_L6","domain":"example", "trace_id":"hafhjkqwjwefk", "is_interrupted": true}'其中各个字段含义如下:
| 字段名 | 类型 | 必要性 | 说明 |
|---|---|---|---|
| header | RequestHeader | 非必要 | 通用请求头 |
| file_name | string | 必要 | 文件名(存放于/agibot/data/var/interaction/audio/,比如 wake.pcm, 文件要求为 24kHz 16 位 单声道的 pcm 文件,需要创建单独文件夹,传入 文件夹名/文件名,比如 file/wake.pcm) |
| priority_level | PriorityLevel | 必要 | 优先级 |
| trace_id | string | 必要 | 如果需要获取播报状态,则需要传入该字段,并将其值作为查询播报状态的参数 |
| is_interrupted | bool | 必要 | 是否打断同等优先级播报,请默认传 true,有队列播报的需求可以使用 false |
播报状态查询接口调用示例
Section titled “播报状态查询接口调用示例”获取 TTS 和音频文件播放状态的方式有两个,可以通过 RPC 接口查询,也可以通过订阅播报状态话题的方式来获取,其中前者更为简单,后者较为准确。
RPC 接口查询播报状态示例如下,需要传入调用 tts 或音频文件播放接口时传入的 trace_id:
curl -i \ -H 'content-type:application/json' \ -X POST 'http://192.168.100.110:59201/rpc/aimdk.protocol.TTSService/GetAudioStatus' \ -d '{"trace_id":"hafhjkqwjwefk"}'返回值中包含 TTSStatus 字段,该字段说明如下:
| 字段名 | 类型 | 说明 |
|---|---|---|
| text | string | 播报文本 |
| priority | uint32 | 最终优先级系数 |
| trace_id | string | 与语音对话的 event_id 匹配,即调用接口传入的 trace_id |
| tts_status | TTSStatusType | 播报状态 |
| domain | string | 调用方来源标识 |
| error_message | string | 错误信息(仅错误状态有效),一般不使用,可以忽略 |
其中 TTSStatusType 枚举值说明如下:
| 枚举值 | 数值 | 说明 |
|---|---|---|
| TTSConfigStatusType_Unknown | 0 | 未知状态 |
| TTSStatusType_Begin | 1 | 开始播放 |
| TTSStatusType_Playing | 2 | 播报中 |
| TTSStatusType_End | 3 | 播报结束 |
| TTSStatusType_Stop | 4 | 暂停播报/取消播报/中断播报 |
| TTSStatusType_Error | 5 | 播报失败 |
| TTSStatusType_InQue | 6 | 在播报队列中,尚未开始播报 |
| TTSStatusType_NOTInQue | 7 | 播报队列无此文本,也不在播报 |
通过该 RPC 接口查询一般会返回 InQue、Playing 和 NOTInQue 状态,播报结束 End 状态存在时间很短一般无法获取到,如果需要获取播报结束状态,可以订阅播报状态话题。
订阅播报状态话题示例如下:
#!/usr/bin/env python3
import rclpyfrom rclpy.node import Nodefrom rclpy.qos import QoSHistoryPolicy, QoSProfile, QoSReliabilityPolicyfrom ros2_plugin_proto.msg import RosMsgWrapper
from aimdk.protocol_pb2 import TTSStatus
class TTSStatusSubscriber(Node): def __init__(self): super().__init__("tts_status_subscriber")
# 音频缓冲区,按 stream_id 分别存储 self.audio_buffers = {} # {stream_id: bytearray()} self.recording_state = {} # {stream_id: bool} 记录是否正在录音
qos_profile = QoSProfile( history=QoSHistoryPolicy.KEEP_LAST, depth=10, reliability=QoSReliabilityPolicy.BEST_EFFORT, )
self.subscription = self.create_subscription( RosMsgWrapper, "/interaction/tts_status/pb_3Aaimdk_2Eprotocol_2ETTSStatus", self.tts_status_callback, qos_profile, )
self.get_logger().info("开始订阅 tts 播报状态。..")
def tts_status_callback(self, msg): try: # 检查序列化类型是否为 pb if msg.serialization_type != "pb": self.get_logger().warn(f"不支持的序列化类型:{msg.serialization_type}") return
# 将 data 字段从 list[bytes] 转换为 bytes tts_status_bytes = b"".join(msg.data)
tts_status = TTSStatus() tts_status.ParseFromString(tts_status_bytes)
self.get_logger().info(f"收到 TTS 播报状态:{tts_status}")
except Exception as e: self.get_logger().error(f"处理 TTS 播报状态消息时出错:{e}")
def main(args=None): rclpy.init(args=args)
tts_status_subscriber = TTSStatusSubscriber()
try: tts_status_subscriber.get_logger().info( "正在监听 TTS 播报状态,按 Ctrl+C 退出。.." ) rclpy.spin(tts_status_subscriber) except KeyboardInterrupt: tts_status_subscriber.get_logger().info("收到退出信号,正在关闭。..") finally: tts_status_subscriber.destroy_node() rclpy.shutdown()
if __name__ == "__main__": main()以上程序依赖 python 协议包 a2_aimdk 和 ros2 协议包 ros2_plugin_proto,相应的包已经放置在 AimDK 开发包的 prebuilt 目录下,python 包使用 pip install prebuilt/a2_aimdk-1.0.0-py3-none-any.whl 安装,ros2 包需要 source prebuilt/ros2_plugin_proto_aarch64/share/ros2_plugin_proto/local_setup.bash 后使用。
请注意,以上程序会接收 ros2 消息,需要设置如下环境变量:
source /opt/ros/humble/setup.bashexport ROS_DOMAIN_ID=232export ROS_LOCALHOST_ONLY=0export FASTRTPS_DEFAULT_PROFILES_FILE=/agibot/software/v0/entry/bin/cfg/ros_dds_configuration.xml播报打断接口调用示例
Section titled “播报打断接口调用示例”此外 TTS 和音频文件播放都可以进行打断,示例如下:
# 需传入指定 trace_id 的播报任务curl -i \ -H 'content-type:application/json' \ -X POST 'http://192.168.100.110:59201/rpc/aimdk.protocol.TTSService/StopTTSTraceId' \ -d '{"trace_id":"hafhjkqwjwefk"}'也可以终止所有 TTS 和音频文件播放,包括当前播报和所有队列中的任务:
curl -i \ -H 'content-type:application/json' \ -X POST 'http://192.168.100.110:59201/rpc/aimdk.protocol.TTSService/StopTTS' \ -d "{}"动作接口调用示例
Section titled “动作接口调用示例”#!/bin/bash
if [ $# -eq 0 ]; then echo "arg error, need motion_id, ./send_motion_id.sh motion_id, example: " echo ./send_motion_id.sh /agibot/data/resources/default/motion/motion_player/default/演讲10s/演讲10s exit 0fi
MC_ID="$1"
if [ "$MC_ID" == "停止动作" ]; then # 如果是“停止动作”,则 motion_id 为空,cmd_reset 设为 true DATA='{ "motion_id": "", "duration_ms": 10000, "cmd_end": true, "cmd_pause": false, "cmd_reset": true }'elif [ "$MC_ID" == "暂停播放器" ]; then # 如果是“暂停播放器”,则 motion_id 保持不变,cmd_pause 设为 true DATA='{ "motion_id": "", "duration_ms": 10000, "cmd_end": true, "cmd_pause": true, "cmd_reset": false }'elif [ "$MC_ID" == "下一个动作" ]; then # 如果是“下一个动作”,则 播放 list 中的下一个动作 DATA='{ "motion_id": "next_motion", "duration_ms": 10000, "cmd_end": true, "cmd_pause": false, "cmd_reset": false }'else # 如果不是“停止动作”或“暂停播放器”,保持原有逻辑 DATA='{ "motion_id": "'"$MC_ID"'", "duration_ms": 10000, "cmd_end": true, "cmd_pause": false, "cmd_reset": false }'fi
# 使用 curl 发送 POST 请求curl -i \ -H 'content-type:application/json' \ -H 'timeout: 1000' \ -X POST http://192.168.100.100:56444/rpc/aimdk.protocol.MotionCommandService/SendMotionCommand \ -d "$DATA"
# 打印发送的数据echo "$DATA"获取动作状态示例如下:
curl -i \ -H 'content-type:application/json' \ -H 'timeout: 1000' \ -X POST http://192.168.100.100:56444/rpc/aimdk.protocol.MotionCommandService/GetMotionStatus \ -d '{}'返回的动作状态中 MotionCommandStatus 枚举值说明如下:
| 枚举值 | 数值 | 说明 |
|---|---|---|
| MotionCommandStatus_IDLE | 0 | 空闲 |
| MotionCommandStatus_START | 1 | 开始执行 |
| MotionCommandStatus_OPERATING | 2 | 运行中 |
| MotionCommandStatus_PAUSE | 3 | 暂停 |
| MotionCommandStatus_STOP | 4 | 停止 |
表情接口调用示例
Section titled “表情接口调用示例”#!/bin/bash
if [ $# -eq 0 ]; then echo "arg error, need emoticon_id, ./a2_PlayerEmoticon.sh emoticon_id, example: " echo ./a2_PlayerEmoticon.sh 1 exit 0fi
curl -i \ -H 'content-type:application/json' \ -H 'timeout: 1000' \ -X POST http://192.168.100.100:59001/rpc/aimdk.protocol.RcEmoticonPlayerService/PlayerEmoticon \ -d '{"emoticon_id":"'$1'","is_need_data":false}'表情接口不支持播放状态查询。
二次开发完全接管
Section titled “二次开发完全接管”退出智元交互链路
Section titled “退出智元交互链路”智元交互链路涉及到的模块一共有两个,分别为 agent 和 interaction,可以简单理解 agent 负责采集音频并进行语音识别,然后与云端模型交互,得到结果后发送给 interaction 模块,interaction 模块再根据结果进行相应的语音播放、动作、表情等操作。
在此模式下,需要让智元的交互程序退出交互链路,仅输出包含本体降噪后的麦克风音频并让出扬声器的控制权,需要进行的操作有两个:
-
调整 agent 模块为 only_voice 模式,所需调用的 rpc 如下(调用后重启机器人生效):
Terminal window curl -i \-H 'content-type:application/json' \-X POST 'http://192.168.100.110:59301/rpc/aimdk.protocol.AgentControlService/SetAgentPropertiesRequest' \-d '{ "contents": { "properties": { "2": "only_voice" } } }'调用后需要重启机器人才能生效,可以待第二步的修改完成后再一块重启即可。(如需恢复,则将其中的 “only_voice” 改为 “normal” 即可)
-
修改配置默认不启动 interaction 模块(修改一次即可,后续无需重复修改)
以下操作均在 ORIN 上执行,首先备份相应配置文件
Terminal window cp /agibot/software/v0/entry/bin/cfg/run_agibot.yaml /agibot/software/v0/entry/bin/cfg/run_agibot.yaml.backupcp /agibot/software/v0/entry/bin/cfg/sm.yaml /agibot/software/v0/entry/bin/cfg/sm.yaml.backup然后在 run_agibot.yaml 文件中删除 default_apps 中的 interaction,在 sm.yaml 文件中删除 function_groups 下 Manager 中的 interaction,其他部分不要修改。
-
还需要关闭监控进程对于 interaction 的监控,修改 /agibot/software/v0/scripts/agent/process_monitor.sh,将其中以下内容移除
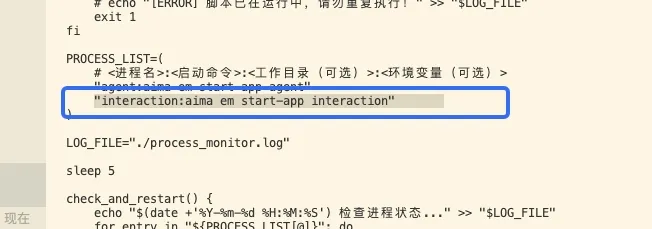
改完成后重启机器人。(如需恢复,则将以上文件还原并重启机器人即可)
以上操作完成后智元交互已退出交互链路。
麦克风音频和扬声器使用方法
Section titled “麦克风音频和扬声器使用方法”注意:要获取以下音频需要机器人开机时至少联网 2 分钟以上完成音频相关鉴权操作,否则将无原始音频输出,如需离线使用,请首先保证该接口有音频输出后再断网
注意:机器人扬声器音量设置不得超过 70%,音量超出此范围扬声器经功放放大后会超额定工作,造成扬声器损坏
获取本体降噪后的麦克风音频示例程序如下:
#!/usr/bin/env python3
import rclpyfrom rclpy.node import Nodefrom rclpy.qos import QoSHistoryPolicy, QoSProfile, QoSReliabilityPolicyfrom ros2_plugin_proto.msg import RosMsgWrapper
from aimdk.protocol_pb2 import ProcessedAudioOutput, AudioVADState
import datetimeimport os
class AudioSubscriber(Node): def __init__(self): super().__init__("audio_subscriber")
# 音频缓冲区,按 stream_id 分别存储 self.audio_buffers = {} # {stream_id: bytearray()} self.recording_state = {} # {stream_id: bool} 记录是否正在录音
# 创建音频文件存储目录 self.audio_output_dir = "audio_recordings" os.makedirs(self.audio_output_dir, exist_ok=True)
qos_profile = QoSProfile( history=QoSHistoryPolicy.KEEP_LAST, depth=10, reliability=QoSReliabilityPolicy.BEST_EFFORT, )
self.subscription = self.create_subscription( RosMsgWrapper, "/agent/process_audio_output/pb_3Aaimdk_2Eprotocol_2EProcessedAudioOutput", self.audio_callback, qos_profile, )
self.get_logger().info("开始订阅降噪音频数据。..")
def audio_callback(self, msg): try: # 检查序列化类型是否为 pb if msg.serialization_type != "pb": self.get_logger().warn(f"不支持的序列化类型:{msg.serialization_type}") return
# 将 data 字段从 list[bytes] 转换为 bytes audio_data_bytes = b"".join(msg.data)
# 使用生成的 protobuf 类解析消息 processed_audio = ProcessedAudioOutput() processed_audio.ParseFromString(audio_data_bytes)
self.get_logger().info( f"收到音频数据:stream_id={processed_audio.stream_id}, " f"vad_state={processed_audio.vad_state}, " f"audio_size={len(processed_audio.audio_data)} bytes" )
# 根据 VAD 状态处理音频 self.handle_vad_state(processed_audio)
except Exception as e: self.get_logger().error(f"处理音频消息时出错:{e}")
def handle_vad_state(self, processed_audio): """处理不同的 VAD 状态""" vad_state = processed_audio.vad_state stream_id = processed_audio.stream_id audio_data = processed_audio.audio_data
# 初始化该 stream_id 的缓冲区(如果不存在) if stream_id not in self.audio_buffers: self.audio_buffers[stream_id] = bytearray() self.recording_state[stream_id] = False
# VAD 状态名称映射 vad_state_names = { AudioVADState.AUDIO_VAD_STATE_NONE: "无语音", AudioVADState.AUDIO_VAD_STATE_BEGIN: "语音开始", AudioVADState.AUDIO_VAD_STATE_PROCESSING: "语音处理中", AudioVADState.AUDIO_VAD_STATE_END: "语音结束", }
stream_names = {1: "内置麦克风", 2: "外置麦克风"}
self.get_logger().info( f"[{stream_names.get(stream_id, f'未知流{stream_id}')}] " f"VAD 状态:{vad_state_names.get(vad_state, f'未知状态{vad_state}')} " f"音频数据:{len(audio_data)} bytes" )
# 根据 VAD 状态处理音频数据 if vad_state == AudioVADState.AUDIO_VAD_STATE_BEGIN: self.get_logger().info("🎤 检测到语音开始") # 开始新的录音,清空缓冲区 self.audio_buffers[stream_id].clear() self.recording_state[stream_id] = True # 添加当前音频数据 if len(audio_data) > 0: self.audio_buffers[stream_id].extend(audio_data)
elif vad_state == AudioVADState.AUDIO_VAD_STATE_PROCESSING: self.get_logger().info("🔄 语音处理中。..") # 如果正在录音,继续添加音频数据到缓冲区 if self.recording_state[stream_id] and len(audio_data) > 0: self.audio_buffers[stream_id].extend(audio_data)
elif vad_state == AudioVADState.AUDIO_VAD_STATE_END: self.get_logger().info("✅ 语音结束") # 添加最后的音频数据 if self.recording_state[stream_id] and len(audio_data) > 0: self.audio_buffers[stream_id].extend(audio_data)
# 保存完整的音频段 if ( self.recording_state[stream_id] and len(self.audio_buffers[stream_id]) > 0 ): self.save_audio_segment(bytes(self.audio_buffers[stream_id]), stream_id)
# 结束录音 self.recording_state[stream_id] = False
elif vad_state == AudioVADState.AUDIO_VAD_STATE_NONE: # 无语音状态,不进行录音 if self.recording_state[stream_id]: self.get_logger().info("⏹️ 录音状态重置") self.recording_state[stream_id] = False
# 输出当前缓冲区状态 if stream_id in self.audio_buffers: buffer_size = len(self.audio_buffers[stream_id]) recording = self.recording_state[stream_id] self.get_logger().debug( f"[Stream {stream_id}] 缓冲区大小:{buffer_size} bytes, 录音状态:{recording}" )
def save_audio_segment(self, audio_data, stream_id): """保存音频段 16kHz, 16 位,单声道 PCM""" if len(audio_data) > 0: timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S_%f")
# 按 stream_id 创建子目录 stream_dir = os.path.join(self.audio_output_dir, f"stream_{stream_id}") os.makedirs(stream_dir, exist_ok=True)
# 生成文件名 stream_names = {1: "internal_mic", 2: "external_mic"} stream_name = stream_names.get(stream_id, f"stream_{stream_id}") filename = f"{stream_name}_{timestamp}.pcm" filepath = os.path.join(stream_dir, filename)
try: with open(filepath, "wb") as f: f.write(audio_data) self.get_logger().info( f"音频段已保存:{filepath} (大小:{len(audio_data)} bytes)" )
# 记录音频文件的时长(假设 16kHz, 16 位,单声道) sample_rate = 16000 bits_per_sample = 16 channels = 1 bytes_per_sample = bits_per_sample // 8 total_samples = len(audio_data) // (bytes_per_sample * channels) duration_seconds = total_samples / sample_rate
self.get_logger().info( f"音频时长:{duration_seconds:.2f} 秒 ({total_samples} 样本)" )
except Exception as e: self.get_logger().error(f"保存音频文件失败:{e}")
def get_buffer_info(self): """获取所有缓冲区的信息(用于调试)""" info = {} for stream_id in self.audio_buffers: info[stream_id] = { "buffer_size": len(self.audio_buffers[stream_id]), "recording": self.recording_state[stream_id], } return info
def main(args=None): rclpy.init(args=args)
audio_subscriber = AudioSubscriber()
try: audio_subscriber.get_logger().info("正在监听降噪音频数据,按 Ctrl+C 退出。..") rclpy.spin(audio_subscriber) except KeyboardInterrupt: audio_subscriber.get_logger().info("收到退出信号,正在关闭。..") finally: audio_subscriber.destroy_node() rclpy.shutdown()
if __name__ == "__main__": main()以上程序依赖 python 协议包 a2_aimdk 和 ros2 协议包 ros2_plugin_proto,相应的包已经放置在 AimDK 开发包的 prebuilt 目录下,python 包使用 pip install prebuilt/a2_aimdk-1.0.0-py3-none-any.whl 安装,ros2 包需要 source prebuilt/ros2_plugin_proto_aarch64/share/ros2_plugin_proto/local_setup.bash 后使用。
请注意,以上程序会接收 ros2 消息,需要设置如下环境变量:
source /opt/ros/humble/setup.bashexport ROS_DOMAIN_ID=232export ROS_LOCALHOST_ONLY=0export FASTRTPS_DEFAULT_PROFILES_FILE=/agibot/software/v0/entry/bin/cfg/ros_dds_configuration.xml其中音频数据为 24kHz 采样率,16 位单声道 PCM 数据(小端序),输出的音频为纯净人声,已经过降噪处理,回声消除等,可以直接用于 ASR 识别。
ProcessedAudioOutput消息包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| header | Header | 通用消息头,包含时间戳和消息 ID |
| stream_id | uint32 | 音频流 ID(1:内置麦克风,2:外置麦克风) |
| vad_state | AudioVADState | 语音活动检测状态 |
| audio_data | bytes | 降噪处理后的 PCM 音频数据 |
AudioVADState 枚举定义:
| 枚举值 | 数值 | 说明 |
|---|---|---|
| AUDIO_VAD_STATE_NONE | 0 | 无语音 |
| AUDIO_VAD_STATE_BEGIN | 1 | 语音开始 |
| AUDIO_VAD_STATE_PROCESSING | 2 | 语音处理中 |
| AUDIO_VAD_STATE_END | 3 | 语音结束 |
扬声器可直接调用操作系统 API 使用,以 aplay 为例,进行文件播放:
aplay -D multiplay_def <file> # 2 声道下行播放,并回传 1 声道回采信号交互接口汇总
Section titled “交互接口汇总”交互相关接口示例文件在 AimDK 包中 examples/agent 和 examples/interaction 目录下均有提供,可参考。
| 接口名/订阅主题 | 接口描述 | 请求消息类型 | 答复消息类型 | 备注 | 通信后端 |
|---|---|---|---|---|---|
/agent/process_audio_output | 订阅降噪后的音频流 | aimdk::protocol::ProcessedAudioOutput | - | 通过 ROS2 订阅获取音频数据 | ros2 |
TTSService.PlayTTS | 文本转语音播放 | PlayTTSRequest | PlayTTSResponse | 支持优先级控制和打断策略 | http |
TTSService.PlayMediaFile | 播放本地音频文件 | PlayMediaFileRequest | PlayTTSResponse | 支持 PCM/WAV 格式文件播放 | http |
TTSService.StopTTS | 停止所有 TTS 播报 | CommonRequest | CommonResponse | 终止当前和队列中的播报任务 | http |
TTSService.StopTTSTraceId | 停止指定 trace_id 的 TTS 播报 | StopTTSTraceIdRequest | CommonResponse | 仅终止指定 trace_id 的播报任务 | http |
TTSService.GetAudioStatus | 查询 TTS 状态 | GetTTSStatusRequest | GetTTSStatusResponse | 获取当前播报状态和队列信息 | http |